Is there a network equivalent of market forces? The crowdsource equivalent (or perhaps generalisation) of Adam Smith's "Invisible Hand"?
When I was in my early teens my school got the new edition of the Encyclopaedia Britannica in over 30 volumes costing around £1,000. It was a huge wealth of authoritative information on just about everything. I spent quite a few lunch hours just reading about stuff.
In the 90s Microsoft bought out Encarta on CD-ROM. It was a lot less information, but it cost a lot less than £1,000. Britannica has been in trouble ever since. Now there is Wikipedia, which is free, a bit less authoritative than Britannica, but has even more information and a great deal more mindshare.
So Britannica has responded by taking a page out of Jimbo Wales's book; its going to start accepting user-generated content, albeit with a stiff editorial barrier to acceptance into the core Encyclopaedia.
Meanwhile the latest controversy on Wikipedia is about whether user-generated content needs more controls. I say "more" because Wikipedia has always had some limits; locked pages, banned editors, and in extreme cases even the deletion of changes (as opposed to reversion, which preserves them in the page history). Increasingly sophisticated editorial policies have been put in place, such as "No Original Research" (originally put in to stop crank science, but now an important guiding principle).
When you look at Wikipedia's history there is a clear trend; every so often Wikipedia reaches a threshold of size and importance where its current level of openness doesn't work. At this point Jimbo Wales adds a minimal level of editorial control. Locked pages, for instance, were added because certain pages attracted unmanageably high levels of vandalism.
It seems that Wikipedia and Britannica are actually converging on the same model from different ends of the spectrum: Wikipedia started out completely open and is having to impose controls to manage quality. Meanwhile the Britannica started out completely closed and is having to allow in user-generated content because comissioning experts to write it is too expensive. Somewhere in the middle is a happy medium that gets good quality content without having to charge subscribers.
Not charging is important. In these days of the hyperlink, an encyclopedia is not just a source of knowledge, it is a medium of communication. If I want to tell people that they should read about the history of the Britannica then I refer to the Wikipedia page because very few people who read this are going to be able to follow a link to a Britannica article (even if I were a subscriber, which I am not).
Wikipedia is often said to have been inspired by the "open source" model in that anyone can edit Wikipedia just as anyone can edit the Linux source code. In fact the cases are not parallel. The GPL allows me to download a copy of the Linux source code, hack it to my heart's content, and give copies of my new version to anyone who wants them. What it does not do is authorise me to upload my version to kernel.org and pass it off as the work of Linus Torvalds. Getting my changes into the official kernel means passing through a strict quality assurance process including peer review and extensive testing on multiple architectures.
So I think that this proposal to create "flagged revisions" for editorial review moves Wikipedia towards the open source model rather than away from it. Anyone will always be able to fork Wikipedia if they wish: the license guarantees it. But the offical version at wikipedia.org will earn increasing trust as the quality assurance improves, just as the official version of the Linux kernel is trusted because of its quality assurance.
My Blog List
Sunday, February 15, 2009
We Don't Know How We Program
I was talking to a colleague from another part of the company a couple of weeks ago, and I mentioned the famous ten-to-one productivity variation between the best and worst programmers. He was surprised, so I sketched some graphs and added a few anecdotes. He then proposed a simple solution: "Obviously the programmers at the bottom end are using the wrong process, so send them on a course to teach them the right process."
My immediate response, I freely admit, was to open and shut my mouth a couple of times while trying to think of response more diplomatic than "How could anyone be so dumb as to suggest that?". But I have been mulling over that conversation, and I have come to the conclusion that the suggestion was not dumb at all. The problem lies not with my colleague's intelligence but in a simple fact. It is so basic that nobody in the software industry notices it, but nobody outside the industry knows it. The fact is this: there is no process for programming.
Software development abounds with processes of course: we have processes for requirements engineering, requirements management, configuration management, design review, code review, test design, test review, and on and on. Massive process documents are written. Huge diagrams are drawn with dozens of boxes to try to encompass the complexity of the process, and still they are gross oversimplifications of what needs to happen. And yet in every one of these processes and diagrams there is a box which basically says "write the code", and ought to be subtitled "(and here a miracle occurs)". Because the process underneath that box is very simple: read the problem, think hard until a solution occurs to you, and then write down the solution. That is all we really know about it.
To anyone who has written a significant piece of software this fact is so obvious that it seems to go without saying. We were taught to program by having small examples of code explained to us, and then we practiced producing similar examples. Over time the examples got larger and the concepts behind them more esoteric. Loops and arrays were introduced, then pointers, lists, trees, recursion, all the things you have to know to be a competent programmer. Like many developers I took a 3 year degree course in this stuff. But at no point during those three years did any lecturer actually tell me how to program. Like everyone else, I absorbed it through osmosis.
But to anyone outside the software world this seems very strange. Think about other important areas of human endeavor: driving a car, flying a plane, running a company, designing a house, teaching a child, curing a disease, selling insurance, fighting a lawsuit. In every case the core of the activity is well understood: it is written down, taught and learned. The process of learning the activity is repeatable: if you apply yourself sufficiently then you will get it. Aptitude consists mostly of having sufficient memory capacity and mental speed to learn the material and then execute it efficiently and reliably. Of course in all these fields there are differences in ability that transcend the mere application of process. But basic competence is generally within reach of anyone with a good memory and average mental agility. It is also true that motor skills such as swimming or steering a car take practice rather than book learning, but programming does not require any of those.
People outside the software industry assume, quite reasonably, that software is just like all the other professional skills; that we take a body of knowledge and apply it systematically to particular circumstances. It follows that variation in productivity and quality is a solvable problem, and that the solution lies in imposing uniformity. If a project is behind schedule then people need to be encouraged to crank through the process longer and faster. If quality is poor then either the process is defective or people are not following it properly. All of this is part of the job of process improvement, which is itself a professional skill that consists of systematically applying a body of knowledge to particular circumstances.
But if there is no process then you can't improve it. The whole machinery of process improvement loses traction and flails at thin air, like Wiley Coyote running off a cliff. So the next time someone in your organisation says something seemingly dumb about software process improvement, try explaining that software engineering has processes for everything except actually writing software.
Update: Some of the discussion here, and on Reddit and Hacker News is arguing that many other important activities are creative, such as architecture and graphic design. Note that I didn't actually mention "architecture" as a profession, I said "designing a house" (i.e. the next McMansion on the subdivision, not one of Frank Lloyd Wright's creations). People give architects and graphic designers room to be creative because social convention declares that their work needs it. The problem for software is that non-software-developers don't see anything creative about it.
The point of this post is not that software "ought" to be more creative or that architecture "ought" to be less. The point is that we need to change our rhetoric when explaining the problem. Declaring software to be creative looks to the rest of the world like a sort of "art envy", or else special pleading to be let off the hook for project overruns and unreliable software. Emphasising the lack of a foundational process helps demonstrate that software really does have something in common with the "creative" activities.
The next challenge for Linux
I was in the local branch of "Currys" (UK electrical and electronic goods chain) recently and had a look at the line-up of computers. They had some little netbooks, and taped next to each one was a little note saying something to the effect of "This runs Linux, so it won't run Windows software". It was a local version of a wider story about Linux:
Of course those of us who use Linux know different. But for most people, Linux is something they might have heard about once or twice, but they didn't pay any attention and couldn't tell you anything about it. Outside its current user base and their immediate circle of friends and family, Linux has zero mindshare.
This is not another lament about Joe Sixpack being too stupid to understand Linux. The problem is not that Linux is too complicated, its that Linux and Windows do things differently. Imagine someone who was raised on Linux; how would they react to Windows? Software installation would seem complicated and geeky, the single desktop would feel claustrophobic, and as for the idea of paying for software...
So I think we need to sort out a message to broadcast to the world and then focus on it. I suggest the following:
- People buy netbooks and then discover that Windows isn't part of the bundle, and they don't like it.
- A teacher found a student handing out Linux CDs and accused him of pirating software.
- A student accidentally bought a Dell laptop with Ubuntu instead of Windows, and complained that she couldn't submit the Word documents required by her college (they say they are happy to accept OpenOffice.org documents) and the installation CD for her broadband service wouldn't install so she couldn't get the Internet (Ubuntu connects to the Internet just fine without it). The local TV station picked up the story as a "consumer rights" case and was amazed to find a virtual lynch mob chasing them for being less than enthusiastic about Ubuntu. They quoted an expert saying that Ubuntu "isn't for everyone" and is more suited to tinkerers than people who just want to get stuff done.
- There are two sorts of computers: Apple Macs, and PCs.
- Apple Macs run Apple software. PCs run Windows software.
- Windows is bundled with PCs. On expensive PCs the bundle might include Office as well.
- If you want extra software, you buy it at a store, take it home and stick the CD in the drive.
Of course those of us who use Linux know different. But for most people, Linux is something they might have heard about once or twice, but they didn't pay any attention and couldn't tell you anything about it. Outside its current user base and their immediate circle of friends and family, Linux has zero mindshare.
This is not another lament about Joe Sixpack being too stupid to understand Linux. The problem is not that Linux is too complicated, its that Linux and Windows do things differently. Imagine someone who was raised on Linux; how would they react to Windows? Software installation would seem complicated and geeky, the single desktop would feel claustrophobic, and as for the idea of paying for software...
So I think we need to sort out a message to broadcast to the world and then focus on it. I suggest the following:
- Linux is an alternative to Windows and Apple. It comes in several flavours.
- Linux isn't easier or harder than Windows, but it is different, and it takes a while to get used to those differences.
- Linux is bundled with a huge range of downloadable free software, including office, graphics and photographic packages.
6 comments:
Wednesday, February 11, 2009
Free Trade Magazine Subscriptions & Technical Document Downloads
|
Browse through our extensive list of free IT - Software & Development magazines, white papers, downloads and podcasts to find the titles that best match your skills; topics include web development, programming, software design and application software. Simply complete the application form and submit it. All are absolutely free to professionals who qualify. | ||||
 Oracle Magazine Contains technology strategy articles, sample code, tips, Oracle and partner news, how to articles for developers and DBAs, and more.... |  The JavaScript Anthology: 101 Essential Tips, Tricks & Hacks - Free 158 Page Preview Get the most out of this complete question-and-answer book on JavaScript.... | |||
 The Common Resource Gap Facing Midsize Companies and the Time-Tested Alliance that Can Save Them In over 800 interviews with midsize companies, IDC has found that while their needs are complex and varied, they share a common interest in... |  Profit Magazine Is distributed to more than 110,000 C-level executives* and provides business leaders with a road map on turning their technology... | |||
 Managed Hosting Services Checklist Be armed with the right questions, market research and criteria to select the right managed hosting solution for your company.... |  Database Trends and Applications Is the leading monthly publication providing corporate information project teams with timely coverage of the technology, intelligence and... | |||
 Supercharge Your Sales Teams Learn how your sales team can better manage their prospects, customers and sales management processes.... |  Improving Customer Support and HelpDesk Efficiencies with On-Demand Remote Support Now you can sit at your desk and solve the toughest support problems, remotely. Sure. You can visit all your employees or customers and... | |||
 Midmarket ERP Solutions Checklist What to ask before you buy Enterprise Resource Planning software.... |  Get the Facts: Real-Time, On-Demand Information for Business Intelligence and Data Integration Learn how to simplify data integration strategies in order to achieve faster, better, more scalable performance with less administration,... | |||
 How to Make Your IT Staff Smarter Learn how on-demand access to trusted technology information empowers IT workforces to solve everyday technical challenges and increase... |  Five Reasons Why Smaller Organizations Should Consider System i (AS/400) High Availability Learn why true High Availability and Disaster Recovery protection are now within reach of even the smallest of businesses.... | |||
 Working Green with Digital Libraries Learn how online tools and content support a green work environment and how technology professionals are working green every day.... |  Today's Financial Crisis and the Impact on Corporate Compliance Learn how Estorian makes it easier for companies to implement and take advantage of the benefits of email archiving.... | |||
 Data Governance Strategies Helping your Organization Comply, Transform, and Integrate Learn how to successfully navigate the unknown waters of Data Governance with these the best practice techniques.... |  HPCWire Is the most recognized and accessed news and information site covering the entire ecosystem of High Productivity Computing (HPC).... | |||
Mapping IP addresses to locations
Have you ever wondered how some websites are able to determine where you visited from? It all begins with the IP address that you belong to when you connect to the internet. Every time you log onto the internet your ISP assigns an IP address to you. This IP address belongs to a specific range that is allotted to regions around the world.
So how do you find out which IP address belongs to a particular location? There are a couple of ways to do this. Solutions include commercial web services as well as free databases which you can download, import and use.
A number of comemrcial offerings are available, but I am not in favor of any solution that involves calling a web service or requesting for the data through some other means remotely. This adds an additional latency to the call, and it also means that your service depends on the service of your vendor and for some websites a downtime of such a service is simply not acceptable. On the positive side, you don't have to worry about how you maintain the data if you are making remote calls to get the location data. There are also commercial solutions that offer the entire database to you for a fee. You can then import this data to your favorite database and make calls as necessary. In this article I will concentrate on a free solution instead.
A free solution
It involves downloading a CSV (comma separated value) file, and then loading this data into a persistent store, say a database. This is comparable to commercial products that offer the same. The free CSV is updated on a daily basis, which is good news. Depending on the accuracy of the data that you need, you will have to refresh the data in your tables daily, weekly or monthly. How much data will be added depends on how many organizations/people register new IP addresses. Lets have a look at the format of this CSV file (the download link is available in the references section)
| From | To | Registered with | When | Country (2) | Country (3) | Country (full) |
| 50331648 | 67108863 | ARIN | 57257 | US | USA | UNITED STATES |
From and To: Hmm? Now what's with these From and To values? An IP address can be converted to a single number. With the IPV4 addressing system, the maximum value of any given value x in x.y.z.a is 255. Lets say we have an IP address 1.2.3.4. To convert this to a number we do the following
1.2.3.4 = (1 * 256 * 256 * 256) + (2 * 256 * 256) + (3 * 256) + 4 = 16909060
The IPV4 system is a 32 bit representation of an IP address. Here is an example illustration of an IP address and its associated bits:
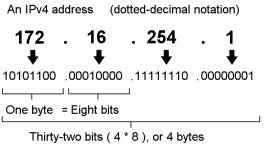
This is what the numbers in the From and To columns represent.
Registered with: The registry that the IP range is associated with. Here are some examples – APCNIC, ARIN, LACNIC, RIPENCC and AFRINIC, IANA
When: Date when this range was assigned in milliseconds.
Country: Two letter and three letter abbreviations as well as the full country name.
Now lets import this data into a database, e.g. PostgreSQL. You can do this with the following command
copy ip_location from 'd:/temp/IpToCountry_withoutID.csv' WITH CSV
This command says to copy the data in the CSV file to the ip_location table (which we have already defined, the structure is available in the reference section). Note that copy is not a SQL standard command – it is specific to PostgreSQL. (Other databases have similar ETL tools available; check the documentation of the one you're using.) Once we have the data, we can write a small program to return the location result, given a IP address. Lets have a look at a code snippet. Here is a utility function to get a location given an IP address.
public void findLocation (String[] args) {
BigInteger base = new BigInteger("256");
if (args.length > 0 && args[0] != null && !args[0].equals("")) {
String ip = args[0];
String[] numberTokens = ip.split("\\.");
int power = 3;
BigInteger bigResult = new BigInteger("0");
for (String number : numberTokens) {
BigInteger bigNumber = new BigInteger(number);
BigInteger raise = raiseToPow(base, power--);
bigNumber = bigNumber.multiply(raise);
bigResult = bigResult.add(bigNumber);
}
System.out.println("Calculated result for " + ip + " is " + bigResult);
printLocationData(bigResult);
} else {
System.out.println("USAGE: java LocationFinder x.y.z.a");
}
}
The method printLocationData() connects to the database and fetches the right values to display. The method raiseToPow() is a utility method that simply raises a number to a given power and returns the result. The code splits the IP address into string tokens containing the numbers that we are interested in. It then generates a result which is looked up in the database using the following query:
select * from ip_location where ? > from_address and ? <>
The "?" is parameterized with the IP address number that we calculated. If the number falls within a particular range, we have what we want. Here is a sample output that the program threw for a given IP address
Calculated result for 66.92.21.32 is 1113330976
Registered with: ARIN
Country: UNITED STATES
So there you have it – free IP to location conversion at your service.
References
Free CSV database: http://software77.net/cgi-bin/ip-country/geo-ip.pl
IPV4 addressing: http://en.wikipedia.org/wiki/IP_address
Sunday, February 8, 2009
When A Synchronized Class Isn’t Threadsafe
Every Java programmer has heard this advice before: “Prefer ArrayList over Vector. Vector is fully synchronized, and as such you’re paying the synchronization penalty even when you don’t need it.”
ArrayList is not synchronized, so when you need it you need to perform synchronization yourself, or alternatively, as the ArrayList javadoc entry says: “… the list should be “wrapped” using the Collections.synchronizedList method.” Something like this:
- List list = Collections.synchronizedList(new ArrayList());
The resulting List will be synchronized, and therefore can be considered safe.
Or is it?
Not really. Consider the very contrived example below.
- final List
list = Collections.synchronizedList( new ArrayList()); - final int nThreads = 1;
- ExecutorService es = Executors.newFixedThreadPool(nThreads);
- for (int i = 0; i <>
- es.execute(new Runnable() {
- public void run() {
- while(true) {
- try {
- list.clear();
- list.add("888");
- list.remove(0);
- } catch(IndexOutOfBoundsException ioobe) {
- ioobe.printStackTrace();
- }
- }
- }
- });
- }
As long nThreads is 1, everything runs just fine. However, increase the number of nThreads to 2, and you start getting this:
java.lang.IndexOutOfBoundsException: Index: 0, Size: 0
at java.util.ArrayList.RangeCheck(Unknown Source)
at java.util.ArrayList.remove(Unknown Source)
at java.util.Collections$SynchronizedList.remove(Unknown Source)
Changing the synchronized List to Vector doesn’t help either. What happened here? Well, individual method calls of synchronized List and Vector are synchronized. But list.add() and list.remove() can be called in any order between the 2 threads. So if you print list.size() after list.add(), the output is not always 1. Sometimes it’s 0, sometimes it’s 2. Likewise, thread 1 may call list.add(), but before it gets a chance to call list.remove(), thread 2 gets into action and calls list.clear(). Boom, you get IndexOutOfBoundsException.
In that example above, the 3 calls to List’s methods have to be atomic. They must happen together as one unit, no interference from other threads, or else we’ll get the IndexOutOfBoundsException again. The fact that the individual methods are synchronized is irrelevant. In fact, we can go back to using the non-synchronized ArrayList, and the program will work, as long as we synchronize properly to make the 3 calls happen as one atomic, indivisible unit of execution:
- synchronized (list) {
- list.clear();
- list.add("888");
- list.remove(0);
- }
The moral of the story is that just because a class is fully synchronized, doesn’t mean it’s threadsafe (UPDATE: as in doesn’t mean your code will be threadsafe from using it–thanks Alex). You still have to be on the look for those sequence of method calls that have to occur atomically, because method level synchronization won’t help in this regard. In other words, watch what you’re doing. (And yes, we should still prefer ArrayList over Vector.)
Threadsafe Iteration & ConcurrentModificationException
Sometimes it’s not so obvious when exactly we’re supposed to synchronize our use of Collections. Ever encountered a ConcurrentModificationException before? I bet it’s probably because your code looks something like this (a.k.a.: why the for-each loop isn’t such a great idea actually):
- final List
list = new ArrayList(); - list.add("Test1");
- list.add("Test2");
- list.add("Test3");
- for(String s : list) {
- if(s.equals("Test1")) {
- list.remove(s);
- }
- }
ConcurrentModificationException will be thrown in this case, even when there’s only a single thread running. To fix this problem, we can’t use the for-each loop since we have to use the remove() method of the iterator, which is not accessible within the for-each loop. Instead we have to do this:
- for(Iterator
iter = list.iterator(); iter.hasNext();) { - String s = iter.next();
- if(s.equals("Test1")) {
- iter.remove();
- }
- }
The point is that iteration is something that we’d probably want to happen atomically–that is, while we’re iterating over a collection, we don’t want other threads to be modifying that collection. If it happens most probably something is wrong with our design.
This is why if you look into the JDK source code, the implementation for Iterator usually checks the expected modification count (i.e.: how many times is this collection supposed to have been modified?) against the collection’s current modification count (how many times this collection has been modified). If they don’t tally, the Iterator assumes that another thread has modified the collection while the iteration is going on, so it throws the ConcurrentModificationException. (This is exactly what happens in our single-threaded case about too by the way–the call list.remove() increases the modification count such that it no longer tallies with the one that the iterator holds (whereas iter.remove() resets the mod count so they still tally.) ConcurrentModificationException is a useful exception–it informs us of a probable fault in our design.
When Volatile Fails
However, ConcurrentModificationException is not 100% reliable. The implementation of Iterator.next() may look something like this:
- public E next() {
- if (modCount != expectedModCount)
- throw new ConcurrentModificationException();
- // other stuff
That is, ConcurrentModificationException is supposed to be thrown when the mod counts don’t tally. But it may not get thrown because the thread on which the modCount check is running is seeing a stale value of modCount. That is, let’s say you have thread A iterating through a collection. Whenever you call iter.next(), it checks that modCount == expectedModCount. But modCount may have been modified by thread B, and yet A is still seeing the unmodified value. If you remember, this is what the volatile keyword is about–it is to guarantee that a thread will always see the most recent value of a variable marked as such.
So why didn’t Joshua Bloch (or whoever took his place in Sun to take care of the Collections API) mark the modCount volatile? That would at least make the concurrent modification detection mechanism more reliable, yes? Well… no. Actually marking modCount volatile won’t help, because although volatile guarantees uptodateness, it doesn’t guarantee atomicity.
What does that mean? Well, if you examine the implementation of ArrayList, you’ll see that methods that modify the list increment the modCount (non-volatile) variable by one (i.e.: modCount++). So theoretically, if we mark modCount as volatile, whenever thread B says modCount++, thread A should always immediately see the value and throws ConcurrentModificationException.
But there is a problem: the increment operator (++) is not atomic. It is actually a compound read-modify-write sequence. So while thread B is in the middle of executing modCount++, it’s entirely possible that the thread scheduler will kick thread B out and decide to run thread A, which then checks for modCount before B has a chance to write back the new value of modCount.
Hidden Iteration
As if things aren’t hairy enough as they are, it’s not always obvious when an iteration over a collection is happening. Sure, it’s probably pretty easy to spot iteration code we’ve written ourselves, so we can synchronize those. However, much less obvious are the iterations that happen within the harmless-looking methods of the Collections API. If you examine the source code of java.util.AbstractCollection class, for example, you’ll see that methods like contains(), containsAll(), addAll(), removeAll(), retainAll(), clear()… practically almost all of them trigger an iteration over the collection. Iteration suddenly becomes a LOT harder to spot!
So What Do We Do?
Sounds pretty hopeless, isn’t it? Well… nah. A very, very smart CS professor named Doug Lea has figured it out for the rest of us. He came up with concurrent collection classes, which handle the problems listed above for the most common cases. These concurrent collections have been part of the standard Java API in java.util.concurrent package. For most cases, they are drop-in replacement for the corresponding non-threadsafe classes in java.util package, and if you haven’t taken a good look at them, it’s time that you do!
Friday, February 6, 2009
Sending SMTP Mail With Java
Introduction : SMTP
So your Java application needs to send a notification mail? Not an uncommon scenario, but how to do it? Luckily this turns out to be pretty easy in it’s simplest form, but SMTP configuration can be the killer. You are of course dependent on being able to access a SMTP mail server and also possessing a little knowledge of the SMTP protocol.
What you need
Some years ago, Sun released the Java Mail API. It doesn’t ship along with the standard Java distribution (yet!) so you will need to download it manually. It can be found here and at the time of writing is at version 1.4.1. The Mail API depends on code from the JavaBeans Activation Framework (JAF) so you’ll need to download that package also. It can be found at this link and at the time of writing is at version 1.1.1. Make sure you add the activation.jar file from the JAF distribution to your Java classpath and you will also need both the mail.jar and smtp.jar files from the Mail API distribution to enable you to send SMTP mail.
The code
The code itself is straightforward enough, but as I said earlier, it’s the SMTP mail server configuration that can turn out to be the problem. Specially if the server is configured to not let you use it indiscriminately to avoid SPAM etc. This will depend on the company policy configuration settings of the SMTP server you are trying to connect to.
OK, here’s a simple example of how it can be done…
- import java.util.Date;
- import java.util.Properties;
- import javax.mail.Message;
- import javax.mail.MessagingException;
- import javax.mail.Session;
- import javax.mail.Transport;
- import javax.mail.internet.InternetAddress;
- import javax.mail.internet.MimeMessage;
-
- public class Main {
- public static void main(String[] args) {
- Properties props = new Properties();
- props.put("mail.smtp.host", "your SMTP mail server here");
- props.put("mail.debug", "true");
-
- Session session = Session.getInstance(props);
-
- try {
- Message msg = new MimeMessage(session);
- msg.setFrom(new InternetAddress("from@here.com"));
- InternetAddress[] address = {new InternetAddress("to@somewhere.com")};
- msg.setRecipients(Message.RecipientType.TO, address);
- msg.setSubject("Mail subject title");
- msg.setSentDate(new Date());
- msg.setText("Message body string");
-
- Transport.send(msg);
- }
- catch (MessagingException e) {}
- }
- }
So, to summarize, start you of by creating a Java Properties object and populating it with relevant configuration information. You need to specify the SMTP host name or IP address for the key “mail.smtp.host”. The “mail.debug” property is useful for development and will give you a hint what’s going wrong should you get into trouble. Proceed on by creating a javax.mail.Session object and passing it your properties object. To create the actual mail message use a javax.mail.internet.MimeMessage object passing along the session instance you just created. Populate the javax.mail.Message object with a valid sender address and receiver address array (mail has only one sender, but can have multiple receivers). Add a mail subject, the timestamp and of course the mail message body. Then all that remains is to actually post the message to the SMTP server. That where the hard part usually begins.
So, not that difficult all in all, but remember to encapsulate the code in a try/catch block and catch the javax.mail.MessagingException exception type for it to compile. Handle errors appropriately, there is a lot that could possibly go wrong here.
SMTP server authentication
As I mentioned earlier, configuration can be the killer. These days most SMTP servers don’t let any old message pass through the system without some kind of policy checking switched on. It is likely that you will need to authenticate your application to the SMTP server when creating the session object. It is also possible that the server will attempt to validate the sender e-mail address your application is using so you need to choose it wisely since it will need to be valid in the mail domain.
To create an authenticated session object you will need to make a few minor adjustments to the code. Create a javax.mail.Authenticator subclass and override the protected method getPasswordAuthentication. By default this method returns null, so you will have to make it return an initialized javax.mail.PasswordAuthentication object containing your username and password.
You also need to tell the session object to use your new authentication class so add the property “mail.smtp.auth” to your Properties object and set its to “true”. Also change the code that creates the session object by using an overloaded version passing both your Properties object and an instance of your new Authenticator subclass. The new code should look something like this:
- import java.util.Date;
- import java.util.Properties;
- import javax.mail.Authenticator;
- import javax.mail.Message;
- import javax.mail.MessagingException;
- import javax.mail.PasswordAuthentication;
- import javax.mail.Session;
- import javax.mail.Transport;
- import javax.mail.internet.InternetAddress;
- import javax.mail.internet.MimeMessage;
-
- public class Main {
- public static void main(String[] args) {
- Properties props = new Properties();
- props.put("mail.smtp.host", "your SMTP mail server here");
- props.put("mail.smtp.auth", "true");
- props.put("mail.debug", "true");
-
- Session session = Session.getInstance(props, new MyAuth());
-
- try {
- Message msg = new MimeMessage(session);
- msg.setFrom(new InternetAddress("from@here.com"));
- InternetAddress[] address = {new InternetAddress("to@somewhere.com")};
- msg.setRecipients(Message.RecipientType.TO, address);
- msg.setSubject("");
- msg.setSentDate(new Date());
-
- msg.setText("Message body string");
-
- Transport.send(msg);
- }
- catch (MessagingException e) {}
- }
- }
-
- class MyAuth extends Authenticator {
- protected PasswordAuthentication getPasswordAuthentication() {
- return new PasswordAuthentication("your username","your password");
- }
- }
And that ought to do it! This code worked fine for me when testing with two separately configured Microsoft Exchange servers (ESMTP , version 6.0.3790.1830 and 6.0.3790.3959) in different mail domains as my SMTP server host, but only if clear text authentication (BASIC) was enabled on the Exchange server.
In both cases the Exchange server checked my sender address and also insisted that my application authenticate itself before allowing it to post.
Monday, February 2, 2009
IBM Websphere portal server 6.1
Last week, a colleage and myself were fortunate to participate at a one day GSE Nordic WebSphere User Group conference held at Bouvet’s offices in Oslo. One of the conference speakers was Stefan Hepper from IBM Germany. Stefan works as the WebSphere Portal Programming Model Architect and leads the programming model part of IBM’s flagship portal product, IBM WebSphere Portal Server. However, more importantly (at least to me), he had the honorable task of working as specification lead for the JSR-168 Portlet version 1.0 specification, and is currently working as specification lead on the new JSR-286 Portlet version 2.0 specification. Naturally, Stefan spoke primarily of the new features in the upcoming WebSphere Portal Server version 6.1 product in the context of JSR-286, but the two aforementioned portlet specifications influence every serious Java based portal server like IBM’s WebSphere Portal Server, SAP Enterprise Portal, Oracle Portal Server, Liferay and JBoss Portal Server, just to name but a few.
However, although Stefan answered a lot of question during his talks, oddly enough, for me the highlight was sharing a taxi and a 20 minute train ride from the conference back to Gardermoen airport (main Oslo airport) where we loosely discussed portlets and portals in depth, and Stefan willingly shared his knowledge with us indiscriminately. It goes without saying that this guy really knows his “stuff”, but it was also quite fascinating to hear how a Java Community Process expert group works in practice. I admit that I knew little of how the JCP works behind the scenes before our conversation, but I got the impression that Stefan is responsible for a whole lot of the final specification work and seems to carry a “heavy burden” by leading the group. However, you won’t find a nicer guy willing to help you with anything related to Java portlet/portal development should you need to call upon him for help.
As you may know, the JSR-168 specification is implemented and supported on almost every Java based portal server. The JSR-286 specification is expected to be finished in april 2008 and introduces quite a lot of new features. If memory serves me correctly, Stefan mentioned that the specifcation API has grown by over 100% since version 1.0. IBM WebSphere Portal Server 6.1 is scheduled for release sometime in the second quarter of 2008 and will support portlets complying with either of the portlet standards. It is also possible to communicate between portlets developed on either standard something that was not possible before between the proprietary IBM Portal API and the JSR-168 implementation.
I also mentioned to Stefan that I thought it was odd that there were so few JSR-168 or porlet related books available on the market. It just so happens that he has co-written and almost finalized a Manning book that was never published. It happens to be available for free download from the Manning web site, but requires registration (free). The book is titled “Portlets and Apache Portals” and it looks good. It also seems to cover WSRP (Web Services for Remote Portlets, version 1.0) and also portlet development using JSR-127 (Java Server Faces).
OpenSource : Good Reasons For Why I Prefer Open Source Software
Introduction
Why do I prefer open source software over proprietary alternatives?
Choice and freedom
Open source software means different things to different people and there any many other good aspects of adopting an open source software strategy. However, I think one of the main reasons I like it boils down to promoting choice and freedom. In general, I don’t like being forced to do anything I don’t want to do. I like to make my own choices.
Choice is good
When developing software the goal is usually to create components that have high cohesion and low coupling. Well designed software enables you to react easily to change, and the lower the correlation between components, the easier it is to alter behavior. Choice is good, so when picking the software I want to use in my everyday life, or within the systems I want to build, I want to experience the same kind of freedom. I want the freedom to use a set of software components that match my specific needs, and not ones forced upon me because they coincidently just happen to be the ones my operating system supports. I want the freedom to replace any of these components at a later date, with better alternatives should I wish to do so, for whatever reason. And should the person, project or company, behind a particular software component on which I depend, decide to abandon support or further production then I have the freedom to carry on development on my own merit since I have the source code available. That is my prerogative. The choice is mine.
You can use the same analogy in other parts of life. If you are a car owner you wouldn’t accept having to fill petrol at only one brand of petrol station because your car happens to be incompatible with other pumps. Such a car just wouldn’t hit the market because nobody would buy it. The reason is apparent. No, you want the choice to shop for the best petrol price or just buy the first thing that comes along. You have the freedom to make that choice.
Paying for software
It’s not about price. Yes, free sounds great and it’s beneficial to have the option to try something for free instead of paying for a trial license, but in general I don’t mind paying for software and have done so many times in the past. However, I’m finished paying for things I no longer need. For example, I have followed Microsoft Windows since 1991 and have purchased licenses for Windows 3.0, Windows 95, Windows 98 and Windows XP among other things. However, I can state with a high degree of certainty that Microsoft Windows XP will be the last Windows license I will ever buy. My company PC happens to use Microsoft Vista and there is absolutely nothing there that I feel I really need. 98% of my everyday needs are covered by using Kubuntu at home. Now, if only Adobe would consider open sourcing some of their products or at least offer their full portfolio on Linux…
M$ basher
So I guess this means I hate Microsoft? I don’t really. I dislike some of their business methods and the FUD they spread, but Microsoft is a corporation that exists to make money. That is it’s purpose - it is not a charity. Many people are unaware that when I left college my idea was to work for a company that developed Microsoft Win32 applications using C. I saw that as a great challenge and something I really wanted to do. I read many books on the subject. However, that never happened for me and I can’t say I lose sleep over it. I think I have gone on to better things, but I think it’s fair to say that I can see the view from both sides of the fence.
I don’t really dislike the Microsoft software portfolio, but I think some of the people using and promoting the software need to take a good, long look at some of the great open source alternatives available out there and assess if the proprietary software they are recommending is really worth the price. Just what is the total cost of ownership for the paying customer?
One thing that does annoy me is when people can’t distinguish between a PC, the Microsoft Windows operating system and the Microsoft Office suite. Of course, this is more down to their own ignorance than anything Microsoft has done [can be disputed]. It’s a shame, but the market for good software alternatives has been so bad for the last 10 years or so that people have become accustomed to seeing these components packaged together that they just see them as one and the same. That’s a tough nut to crack.
Moving along
The open source world is not what it once used to be. It’s still a movement, a rebellion in a way, but it is definitely growing. Open source software recently reached the boardrooms and more and more companies are reaping the benefits of developing products under an open source license. But let’s not beat about the bush. There is a lot more money involved in open source development today than ever before. Large corporations like Sun and IBM aren’t giving away software to be nice. It is clear that the mindset has changed and so have the business models.
As I said earlier, there are many other good reasons why open software is preferable. However, I can only cover so much in one posting. However, I think the steady rise of open source software is good news for developers, corporations and consumers alike. For the first time in many years they now have the freedom to choose between several viable alternatives and more and more of them seem to be breaking free of their shackles.
Monday, January 19, 2009
Compiler Class
The java.lang.Compiler class provides a way to access an embedded Java compiler, which is loaded at startup if the java.compiler system property is defined.
The value of the property should be the name of a dynamically linked library implementing the compiler.
There is no predefined compiler; you must provide one.
Runtime Class
You can't construct a Runtime instance yourself. A Runtime object is obtained by calling the static method Runtime.getRuntime(). By using a Runtime instance, you can
- Execute a subprocess.
- Exit the program.
- Load a dynamically linked library.
- Run the garbage collector or finalize objects.
- Estimate free memory.
- Control program tracing.
- Localize streams (make them translate from Unicode to the local character set).
A Runtime object can be used to execute another system process by way of the exec() method (in four flavors) that returns a java.lang.Process object.
The Process instance is useful for attaching to the standard input, output, and error streams of the new process.
You can also kill the subprocess, wait for it to terminate, and retrieve its exit code, all by way of the Process object.
The process exists outside the Java virtual machine. It is not a Thread but a separate system process, and some aspects of its behavior may be system-dependent.
You can use a Runtime object to load a dynamically linked library. This is necessary in order to use native methods in Java.
The methods traceInstructions() and traceMethodCalls() request that the Java virtual machine print trace information about each instruction or each method call that gets executed, respectively. Where the output ends up or whether tracing is supported at all is implementation-dependent.
While you can use a Runtime object to run the garbage collector or finalize any outstanding objects (gc() and runFinalization() methods), this should not normally be necessary, since the Java environment runs a separate thread whose purpose is to finalize and garbage collect when necessary.
Furthermore, although the exit() method can be used to exit the program, it should normally be avoided, except to specify an exit code upon normal termination of a stand-alone program. Low-level methods and applets generally throw exceptions instead.
System Class
There are no instances of the System class. The System class allows you to
- Access the standard input, output, and error streams.
- Exit the program.
- Load a dynamically linked library.
- Run the garbage collector or finalize objects.
- Access system Properties.
- Access the SecurityManager.
- Perform system-dependent array copy and time-check operations.
The standard input, output, and error streams of your Java application or applet are accessed as System.in, System.out, and System.err.
These class variables are PrintStream objects (see java.io, below), allowing your application to perform the usual UNIX-style I/O.That's not much use in a finished applet, since an applet embedded in a web page is typically disallowed from doing anything useful with these streams. They are handy for debugging in appletviewer, and also in stand-alone Java applications.
Java also maintains some system properties, accessible through the System class. These take the place of environment variables and anything else in the system that is relevant to the Java environment.
The static method getProperties() returns a java.util.Properties object describing the system properties. For example, the properties can be listed by a little program such as the following:
public class Props
{
public static void main( String args[] )
{
System.getProperties().list(System.err);
}
}
This program results in a list of system properties:
-- listing properties --
java.home=/mnt2/java
java.version=1.0
file.separator=/
line.separator=
java.vendor=Sun Microsystems Inc.
user.name=korpen
os.arch=sparc
os.name=Solaris
java.vendor.url=http://www.sun.com/
user.dir=/nfs/grad/korpen/www/java
java.class.path=.:/home/grad/korpen/www/java:/mnt2/ja...
java.class.version=45.3
os.version=2.x
path.separator=:
user.home=/homes/ritesh
Use the static method getProperty() to get individual properties by name.
Cloning Objects | Cloneable Interface
the Cloneable Interface
Besides overriding the clone() method in java.lang.Object, a class may implement the interface Cloneable to indicate that it makes sense to clone this type of object.
The interface is an empty one.
You don't need to supply any methods to conform to Cloneable, although you may want to override the default clone() method.
Other classes can tell whether a class implements Cloneable by examining its class descriptor (an instance of the class Class).
Security Manager
By extending the abstract class java.lang.SecurityManager, you can specify a security policy for the current Java program.
Any code loaded over the Internet by your program is then subject to that policy, for example.
A Java program has only one SecurityManager. You can look up the current SecurityManager by calling System.getSecurityManager(). This method returns null to indicate that the default security policy is being used.
The default policy is rather lax. However, you can install a custom security manager. This allows you to do the following, among other things:
- Prevent Java code from deleting, writing, or reading certain files.
- Monitor or disallow certain socket connections.
- Control which Threads may access which other Threads or ThreadGroups.
- Control access to packages, and to system properties.
For example, the method call that checks whether the calling code is allowed to delete a certain file is declared:
public void checkDelete( String file );
The method must either return quietly, or throw a SecurityException. This is typical of the public methods in class SecurityManager.
To provide a custom security manager, write a subclass of SecurityManager and override some of its check methods. Although the SecurityManager class is abstract, none of its methods are abstract.
You still want to override a fair number of them, though, since the check methods inherited from SecurityManager always throw a SecurityException. You don't have to call on these methods yourself for the security manager to be effective.
Once the security manager is installed, various library methods call on it to check for security clearance. To install your SecurityManager, create an instance of it, and call System.setSecurityManager().
Here is a little program (SMDemo.java) that demonstrates how to use a custom security manager. You should create files named DELETEME and KEEPME before running the program:
import java.io.File;
class MySecurityManager extends SecurityManager
{
public void checkDelete( String file )
{
// Only allow the file "DELETEME" to be deleted.
if ( !file.equals( "c:\\DELETEME.txt" ) )
throw new SecurityException( "cannot delete: " + file );
}
// Override many more checkXXX() methods here...
}
public class SMDemo
{
public static void main( String argv[] )
{
MySecurityManager m = new MySecurityManager();
File deleteme = new File("c:\\DELETEME.txt" );
File keepme = new File("c:\\KEEPME.txt" );
System.setSecurityManager( m );
deleteme.delete(); // Should be OK.
keepme.delete(); // Should get a SecurityException.
System.exit(0);
}
}
After you execute the program, you should see that the file DELETEME is gone and the KEEPME file is still there, the program having triggered a SecurityException upon trying to delete it.
Classes at Runtime
Even at runtime, it is possible to access certain features of a class. This is done by way of the class Class, which implements a class descriptor object for a Java class.
You can get a class descriptor from an existing class either by using the getClass() method of java.lang.Object or by calling the static method Class.forName():
Class stringClass = Class.forName("String");
Using a class descriptor, you can find out:
- The class name
- The superclass
- Whether the class is actually an interface
- Which interfaces the class implements
- Which ClassLoader originated this class
There is also a way to instantiate new objects from the class descriptor: the newInstance() method. This has the limitation that no arguments can be passed to the constructor, so it fails unless the class has an accessible constructor which takes no arguments.
There also doesn't seem to be any way to use the class descriptor to produce a valid operand for the right-hand side of instanceof.
Class java.lang.ClassLoader is meant to provide a way to load classes at runtime from a user-defined source. It is an abstract class.
A subclass must implement the loadClass() method to load an array of bytes from somewhere and then convert it into a class descriptor by calling resolveClass() and defineClass().
How To Make JAR File | Jar File Creation
To create .jar file that is executable and platform independent
Java Archive file.
First you need to Create manifest file that having information like
main-class (class having main method), version etc..
Ex: manifest.fs
Main-Class: HelloWorld
Version: 1.0
To create .jar file you need to use 'jar' command located at
\jdk\bin directory.
Usage:
jar {ctxu}[vfm0Mi] [jar-file] [manifest-file] [-C dir] files ...
Options:
-c create new archive
-t list table of contents for archive
-x extract named (or all) files from archive
-u update existing archive
-v generate verbose output on standard output
-f specify archive file name
-m include manifest information from specified manifest file
-0 store only; use no ZIP compression
-M do not create a manifest file for the entries
-i generate index information for the specified jar files
-C change to the specified directory and include the following file
If any file is a directory then it is processed recursively.
The manifest file name and the archive file name needs to be specified
in the same order the 'm' and 'f' flags are specified.
Example 1: to archive two class files into an archive called classes.jar:
jar cvf classes.jar Foo.class Bar.class
Example 2: use an existing manifest file 'mymanifest' and archive all the
files in the foo/ directory into 'classes.jar':
jar cvfm classes.jar mymanifest -C foo/ .
Java Archive file.
First you need to Create manifest file that having information like
main-class (class having main method), version etc..
Ex: manifest.fs
Main-Class: HelloWorld
Version: 1.0
To create .jar file you need to use 'jar' command located at
Usage:
jar {ctxu}[vfm0Mi] [jar-file] [manifest-file] [-C dir] files ...
Options:
-c create new archive
-t list table of contents for archive
-x extract named (or all) files from archive
-u update existing archive
-v generate verbose output on standard output
-f specify archive file name
-m include manifest information from specified manifest file
-0 store only; use no ZIP compression
-M do not create a manifest file for the entries
-i generate index information for the specified jar files
-C change to the specified directory and include the following file
If any file is a directory then it is processed recursively.
The manifest file name and the archive file name needs to be specified
in the same order the 'm' and 'f' flags are specified.
Example 1: to archive two class files into an archive called classes.jar:
jar cvf classes.jar Foo.class Bar.class
Example 2: use an existing manifest file 'mymanifest' and archive all the
files in the foo/ directory into 'classes.jar':
jar cvfm classes.jar mymanifest -C foo/ .
Subscribe to:
Posts (Atom)
It's because of people like this that make me hope and pray the "year of the linux desktop" never come. Keep them out of linux and on the Windows sandbox where they belong. I dont want to worry about spyware on my linux boxes
I agree. I like how it is now, and to be honest I just jumped to Linux about a month ago. I'm using Ubuntu, and I think it is far better than any Windows I have used.
I don't want spyware, or anything on my OS, because if Linux was mainstream, more attention means more issues. It would be harder, but it would be done.
Most people don't want to work on a computer, but rather they want to do something with the computer. Write a letter, organize photos, play music, maybe some more advanced work like drawing or designing or composing. The untold story about Linux is how many applications there are that just come with the basic install. Windows and even Mac have some basic stuff but one very quickly runs out of new things to do.
Ha! you think a Linux person thinks installations are complicated on Windows. I'm a developer that has mostly used Windows and I think the same about installing something on Linux. It seems like I always need to edit some config file to get an application to work. Windows, double-click, follow directions. What could be simpler?
Agreed. Double clicking on the install button to install an application does sound about the simplest thing you can possibly do.
Of course, it describes the process of installing something on linux much more accurately than it does installing it on windows.
Windows approach to installing software:
1. Acquire the software. After purchasing, this will either involve waiting days for a CD to arrive or downloading an installer from their site.
2. Run the install process. Chances are this will be different from the install process for most other applications, but will mostly involve you inserting a CD and getting it to autoplay or double clicking on the installer you downloaded. Sometimes it won't autoplay and you'll have to open the CD.
3. Click through a bunch of next buttons, possibly filling out data as you go but more likely just automatically clicking next.
Simple, huh? On linux:
1. Acquire the software. This involves firing up the package manager program, typing the software's name (or a general description if you don't know the name) into the search box and double clicking on the result.
2. Installing the software. This involves clicking the apply button.
To Ryan and Dave,
I think the point being made is that Linux and Windows each have their strong points and weak points, and someone familiar with one may not be familiar with the other. It's actually a really interesting point that I haven't seen before.
If I were to raise my children using Linux, they would know that to install VLC Media Player, they would type "sudo apt-get install vlc" in the terminal, zap! It's in their Applications menu. But put them on a Windows computer, and they have to deal with an EXE file, tell it where to install to, choose installation options, and click a whole bunch of buttons.
That's not to say that either is harder than the other - they're both just different.